We are a research community developing scientifically grounded research outputs and robust deployment infrastructure for broader impact evaluations.
This project aims to investigate how to systematically characterize the complexity and behavior of AI benchmarks over time, with the overarching goal of informing more robust benchmark design. The ...
Learn more →This project addresses the need for a structured and systematic approach to documenting AI model evaluations through the creation of "evaluation cards," focusing specifically on technical base syst...
Learn more →The Eleuther Harness Tutorials project is designed to lower the barrier to entry for using the LM Evaluation Harness, making it easier for researchers and practitioners to onboard, evaluate, and co...
Learn more →
Our initial post launching the Science of Evaluations workstream outlined a research agenda to document the scientifi...

As AI models advance, we encounter more and more evaluation results and benchmarks—yet evaluation itself rarely takes...
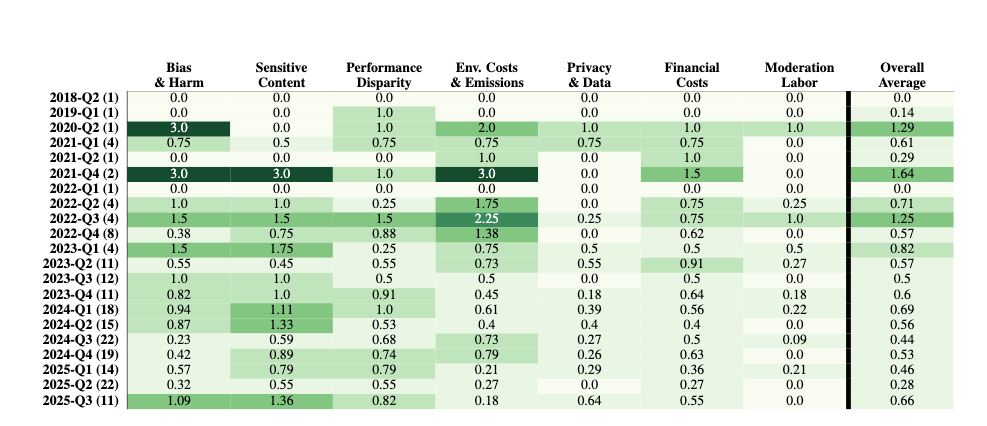
As AI continues to grow more powerful, who carries the hidden social costs of its effects?
This workshop focuses on AI evaluation in practice, centering the tensions and collaborations between model developers and evaluation researchers and aims to surface practical i...
Help us build the first unifying, open database of LLM evaluation results! Convert evaluation data from leaderboards, papers, or your own runs into a shared format — and join as...
Researchers, practitioners, and students are welcome to contribute to our mission. Send us an email to learn more about getting involved.
evalevalpc@googlegroups.comHosted By
